

This article will dive deep into the OpenSearch Keyword field in Java from the CodeSloth GitHub code sample repository using the opensearch-java package. We’ll explore how to define keyword mappings and look at the tokens they produce when data is indexed into them. Finally we will answer the most confusing OpenSearch question by highlighting the difference between OpenSearch keyword and text field data mappings at search time.
At time of writing, Elastic.co documentation is far richer than that published by OpenSearch. Therefore a combination of links between the two vendors may be provided to reference the concepts discussed. These offerings are currently functionally equivalent so the word ElasticSearch and OpenSearch may be used interchangeably.
What is an OpenSearch Keyword field in Java?
The keyword field data type is a simple data type that we can use to index raw Java strings. It supports exact match search; producing a single unmodified token from the given input. We will take a closer look at what a token is shortly.
To use this data type, simply define a class or record with a string member, such as the ProductDocument in the KeywordDemo Java test Project.
package KeywordDemo.Documents;
import java.util.Objects;
/**
* A sample document that contains a single keyword field that is explored during multiple tests within the suite.
*/
public class ProductDocument implements IDocumentWithId {
private String id;
private String name;
private int rank;
...
/**
* Gets the product name.
* This string property will be mapped as a keyword.
* Conceptually this property may represent the name of a product.
*
* @return The product name
*/
public String getName() {
return name;
}
/**
* Sets the product name.
*
* @param name The product name
*/
public void setName(String name) {
this.name = name;
}
}
How is a Keyword Mapped in Java?
Firstly, lets look at how the testing code is defined in the CodeSloth code samples repo:
- Each test file / method is responsible for defining the type of mapping that it will use
- However, the responsibility for creating and managing an index sits within the
OpenSearchTestIndex - We use the
OpenSearchIndexFixtureto create anOpenSearchTestIndex, and pass through the mapping that the test requires
This relationship is demonstrated in the Mermaid diagram below.
flowchart TD
subgraph KeywordIndexingTests
A[Test Method] --> B["Define mapping lambda
for keyword field"]
B --> C["Call fixture.createTestIndex
with mapping lambda"]
end
subgraph OpenSearchIndexFixture
D[createTestIndex method] --> E["Create new
OpenSearchTestIndex"]
E --> F["Pass mapping lambda to
OpenSearchTestIndex"]
end
subgraph OpenSearchTestIndex
G[createIndex method] --> H["Build TypeMapping
from lambda"]
H --> I["Configure keyword
field properties"]
I --> J["Create index with mapping"]
end
C --> D
F --> GThe creation of the keyword mapping is straightforward. As is the case with all mappings, we create a TypeMappingBuilder, specify our definition and call .build() to produce a TypeMapping.
In keywordMapping_IndexesASingleTokenForGivenString we invoke the properties method on the Consumer‘s TypeMappingBuilder
try (OpenSearchTestIndex testIndex = fixture.createTestIndex(mapping ->
mapping.properties("name", Property.of(p -> p.keyword(k -> k))))) {
Here, we can see that the createTestIndex method on the fixture is being called. It is given a lambda that defines a property called name. The second parameter uses Property.of to produce a Property.builder, which in turn uses a KeywordProperty.builder to define the type.
Sigh. I miss the strongly-typed structure of OpenSearch in .Net. This blog post demonstrates the keyword mapping in .Net for reference. Perhaps stringly-typed properties will be less of a maintenance and traceability burden with the introduction of tooling like Cursor?
This is passed through to the OpenSearchTestIndex
/**
* Creates the index with the specified mapping and settings.
*
* @param mappingConsumer Consumer to configure the mapping
* @param settingsConsumer Consumer to configure the settings (optional)
* @throws IOException If an I/O error occurs during the operation
*/
public void createIndex(Consumer<TypeMapping.Builder> mappingConsumer, Consumer<IndexSettings.Builder> settingsConsumer) throws IOException {
TypeMapping.Builder mappingBuilder = new TypeMapping.Builder();
mappingConsumer.accept(mappingBuilder);
CreateIndexRequest.Builder requestBuilder = new CreateIndexRequest.Builder()
.index(name)
.mappings(mappingBuilder.build());
// Always set shard count to 1
IndexSettings.Builder settingsBuilder = new IndexSettings.Builder()
.numberOfShards("1")
.numberOfReplicas("0");
if (settingsConsumer != null) {
settingsConsumer.accept(settingsBuilder);
}
requestBuilder.settings(settingsBuilder.build());
var request = requestBuilder.build();
OpenSearchRequestLogger.LogRequestJson(request);
CreateIndexResponse response = openSearchClient.indices().create(request);
if (!response.acknowledged()) {
throw new IOException("Failed to create index: " + name);
}
}
In summary this method:
- Produces a
TypeMapping.Builderthat is initialized using the mappingConsumer- This is what we used to define the
keywordmapping in our test method
- This is what we used to define the
- A
CreateIndexRequest.Builderis initialized with theGUIDtest index name and the desired mappings - An
IndexSettings.Builderis initialized, setting a single shard with no replicas. This avoids the cluster going into a yellow state- If available, test specific settings are applied. These will be used in future blog post tests.
- The request is built, and executed using the OpenSearch Client’s
.indices().create(...)method
Inspecting the OpenSearch Keyword Mapping Using CodeSloth Samples
Debugging the test samples is very easy, thanks to the OpenSearchResourceManagementExtension. This class is responsible for calling docker-compose to launch an OpenSearch cluster locally on your machine, along with OpenSearch Dashboards (a tool that can be used to manually send and debug queries on the cluster).
Open the codesloth-search-samples-java project in IntelliJ IDEA Community Edition.
Open pom.xml and sync Maven dependencies, to ensure packages are up to date.
Next, open KeywordIndexingTests.java and locate keywordMapping_IndexesASingleTokenForGivenString.
Place a breakpoint on the first line of the test by either clicking on the line number, or use the keyboard shortcut CTRL + F8 after placing the cursor on the line.
Click the green arrow to the side of the test, and then select Debug.
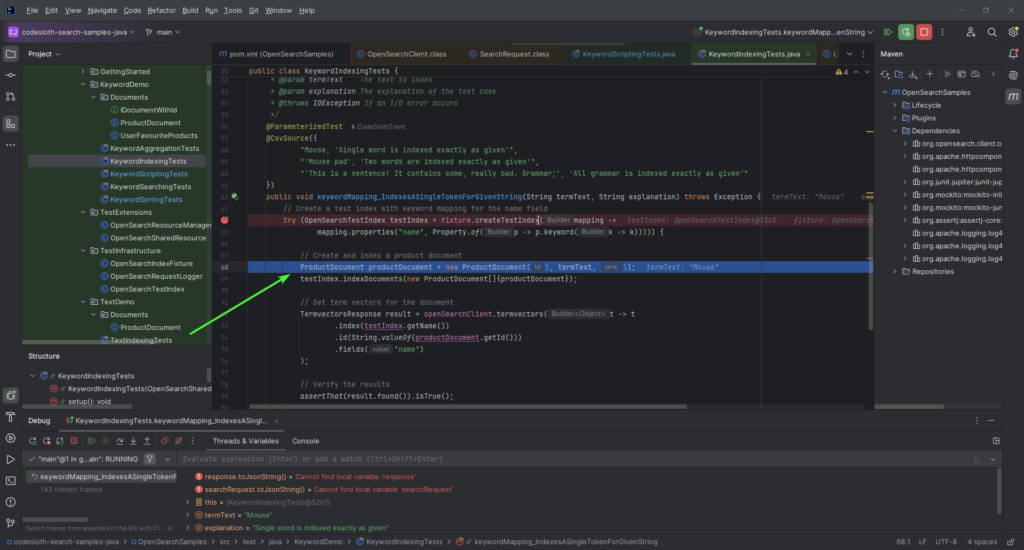
Press F8 once, to step over the index creation logic. This will place your debugger on the line that creates a new ProductDocument.
Open your Chrome browser, launch ElasticSearch Head and locate the test index. You can learn more about ElasticSearch Head here. The index name will be a GUID, as below.
Select Info -> Index Metadata.
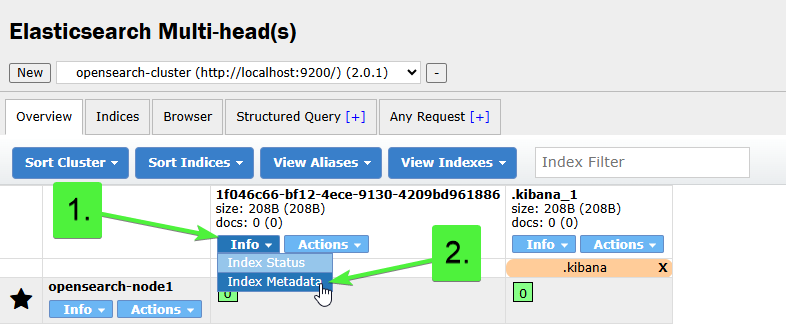
Locate the Mappings section. This typically sits under Settings in the JSON content.
The keyword mapping for our document looks like this:
"mappings": {
"_doc": {
"properties": {
"name": {
"type": "keyword"
},
...
}
}
}
Yep. That’s it. Pretty basic huh?
OpenSearch Keyword Analysis (or Lack Thereof)
Despite keywords being simple, they are likely going to form a common part of your toolset if you require exact string matching in your search experience. This is because the keyword analyser uses a keyword tokenizer that does nothing. It spits out a single token of whatever you have given it.
When a search is peformed in the OpenSearch inverted index, your search terms (tokens) must match an indexed token exactly, including case and punctuation. This is true even for complex full-text search experiences; these just index many different tokens for a given input.
If you search for “Cat”, but have indexed the token “cat” no document will be matched.
This blog post describes the parts of an OpenSearch Analyser in more detail, and how you can create your own to refine the search experience. Typically we perform lowercase normalization (even for exact match searches) to give our search terms the best chance of matching.
Let’s take a closer look at the the keyword token in action!
Observing the Keyword Token in Java
The test case below will index a single document that contains a parameterised termText string. The CodeSloth code sample actually evaluates different types of string inputs, but we’ve focused on the most complex one for the example below.
The complexity of the string can be observed through its use of:
- Capital and lowercase letters
- Punctuation such as exclamation mark, comma, full stop and semicolon
- Known English Stop Words (words removed from tokenisation by a stop token filter)
Each of these components could be subject to omission or modification during text based tokenisation.
@ParameterizedTest
@CsvSource({
... other examples ...
"'This is a sentence! It contains some, really bad. Grammar;', 'All grammar is indexed exactly as given'"
})
public void keywordMapping_IndexesASingleTokenForGivenString(String termText, String explanation) throws Exception {
// Create a test index with keyword mapping for the name field
try (OpenSearchTestIndex testIndex = fixture.createTestIndex(mapping ->
mapping.properties("name", Property.of(p -> p.keyword(k -> k))))) {
// Create and index a product document
ProductDocument productDocument = new ProductDocument(1, termText, 1);
testIndex.indexDocuments(new ProductDocument[]{productDocument});
// Get term vectors for the document
TermvectorsResponse result = openSearchClient.termvectors(t -> t
.index(testIndex.getName())
.id(String.valueOf(productDocument.getId()))
.fields("name")
);
// Verify the results
assertThat(result.found()).isTrue();
var resultString = result.toJsonString();
// Extract tokens and their frequencies
Map<String, TermVector> termVectors = result.termVectors();
String tokensAndFrequency = termVectors.entrySet().stream()
.flatMap(entry -> entry.getValue().terms().entrySet().stream()
.map(term -> term.getKey() + ":" + term.getValue().termFreq()))
.collect(Collectors.joining(", "));
String expectedTokenCsv = termText + ":1";
assertThat(tokensAndFrequency).as(explanation).isEqualTo(expectedTokenCsv);
}
}
When we started debugging the test earlier, we saw that a test index was created with a Keyword mapping. As we continue to step through the test we can see that it:
- Creates a
ProductDocumentwith the parameterisedtermText - Indexes this document (saves it into the index so it can be tokenised)
- Issues a
termVectorsquery, specifying the test index name, the ID of the document and the field name- A term vectors query returns us information about the terms (tokens) that have been created for a particular field in a document
- Asserts that a single token is produced matching the
termText
Continue pressing F8 until you have stepped over the call to testIndex.indexDocuments
Return to Elastic Chrome Head and search the test index
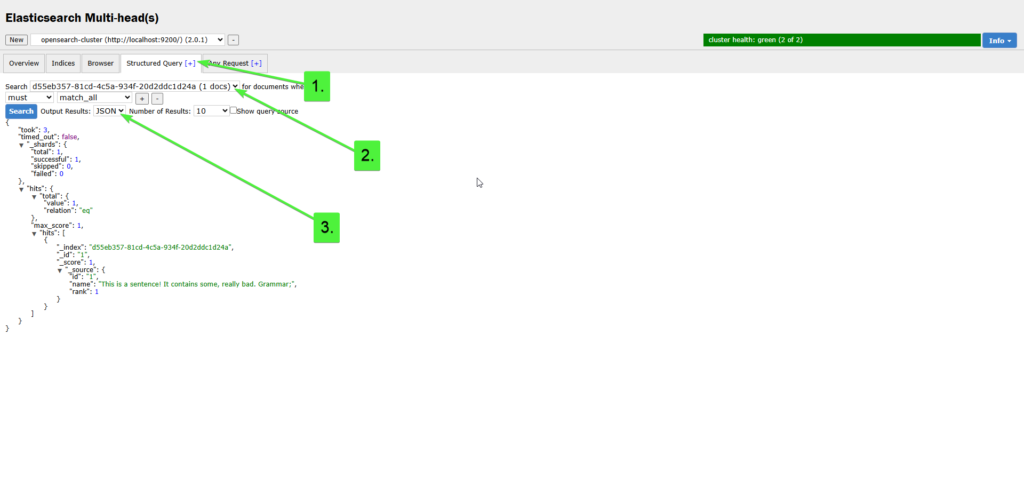
We can observe the indexed document using ElasticSearch Head’s Structured Query tab:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "d55eb357-81cd-4c5a-934f-20d2ddc1d24a",
"_id": "1",
"_score": 1,
"_source": {
"id": "1",
"name": "This is a sentence! It contains some, really bad. Grammar;",
"rank": 1
}
}
]
}
}
As we can see, the name field of the _source document contains exactly the termText that the test was given. It is important to understand though, that the _source document only contains the original indexed data and is not used to perform the search itself!
To confirm that our field has produced a single token we can query the Term Vectors API using TermVectorsAsync on the OpenSearch client. This will return us each generated token and the number of times that the token appeared in a given field for a specific document.
Continue pressing F8 until you have stepped over the resultString assignment.
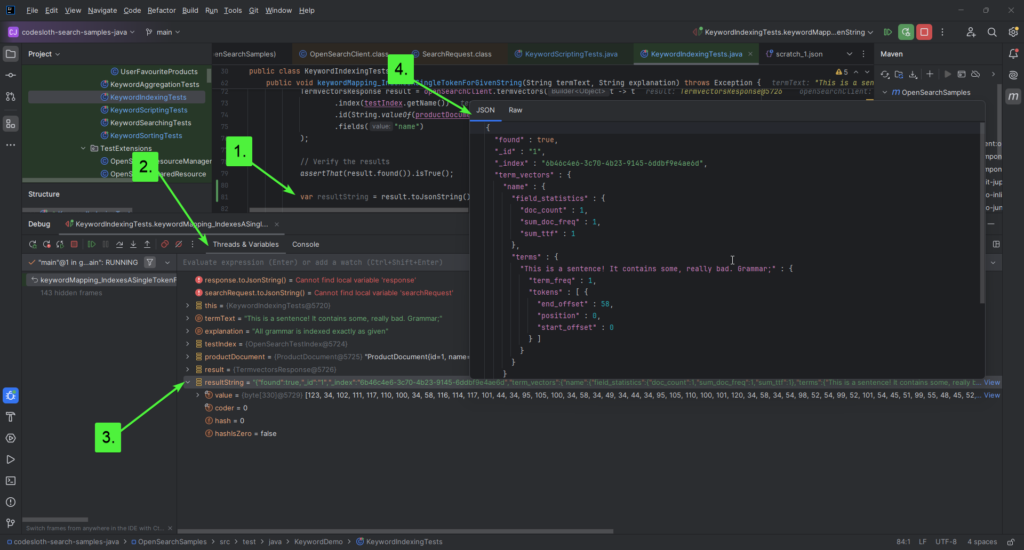
You’ll find the following information captured:
{
"found" : true,
"_id" : "1",
"_index" : "6b46c4e6-3c70-4b23-9145-6ddbf9e4ae6d",
"term_vectors" : {
"name" : {
"field_statistics" : {
"doc_count" : 1,
"sum_doc_freq" : 1,
"sum_ttf" : 1
},
"terms" : {
"This is a sentence! It contains some, really bad. Grammar;" : {
"term_freq" : 1,
"tokens" : [ {
"end_offset" : 58,
"position" : 0,
"start_offset" : 0
} ]
}
}
}
},
"took" : 0,
"_version" : 1
}
This response confirms that we have a single term in the response (found under the terms property), which reflects our original (unmodified) string. The term_freq indicates that this token has only been found once, which makes sense because the whole string has created a single token.
Our test above asserts this for us, by concatenating the parameterised termText against the value 1 and performing an equivalence comparison against the results of the term vector query, which are formatted in the same way.
OpenSearch Keyword vs Text
It can be confusing to understand the difference between keyword and text mappings when starting out with OpenSearch. This confusion then worsens when you start to consider term v.s. match query types for executing a search.
From an indexing perspective, remember:
Keywords: produce a single token. The keyword analyser does nothing to a given stringText: may produce more than one token. The default analyzer is the standard analyser
The details of searching keyword mappings can be found in this article on querying the keyword field data type. In summary:
| Keyword mapping | Text Mapping | |
| Term query | Exact match search | Will only match documents that produce a single token. This means that strings which contain spaces or punctuation will not match, as the standard analyzer creates shingles from the input string |
| Match query | Exact match search. Query string is not tokenised. | Scored search on tokens. Query string is tokenised. |
Sloth Summary
OpenSearch Keywords are a powerful tool for exact match text search. They are often confused with text mappings, but are a much simpler version to begin working with. Remember that you might need to define a custom analyzer with a lowercase token filter if you do not want to perform case sensitive exact match searching!
We learned how to create an index that has an OpenSearch keyword field using a Java POJO, index data into it and observe the tokens produced. For more information on querying keyword data check out this article; a Java article will be published in future.
Remember to check out the GitHub links in the code samples page for the complete references to snippets included in this article!