

This article will refer to ElasticSearch and OpenSearch synonymously.
A wise Code Sloth should pay attention to the basic concepts discussed in this article before moving on. If you’re already across them however, feel free to head to the Sloth Summary at the bottom of this post to jump into the tutorials!
What is Indexing in OpenSearch?
To write a series on indexing data into OpenSearch, we’d better start by defining the word itself. Indexing sounds much more complex than it ought to. From an application engineering perspective it’s simply the act of storing data in your OpenSearch cluster; the equivalent of putting data into a database table.
How you structure your data for indexing, or what happens after you issue an index request to the cluster on the other hand is not quite as simple. The complexities of nodes, sharding, replication, mappings and the like will be discussed alongside practical tutorials in the coming articles of this series.
How is Data Stored in OpenSearch?
If indexing talks about storing data in OpenSearch, where does the data actually get stored?
Unlike a database which stores columnar data in tables, OpenSearch stores JSON formatted data in documents. Let’s take a look at these concepts in the diagram below.
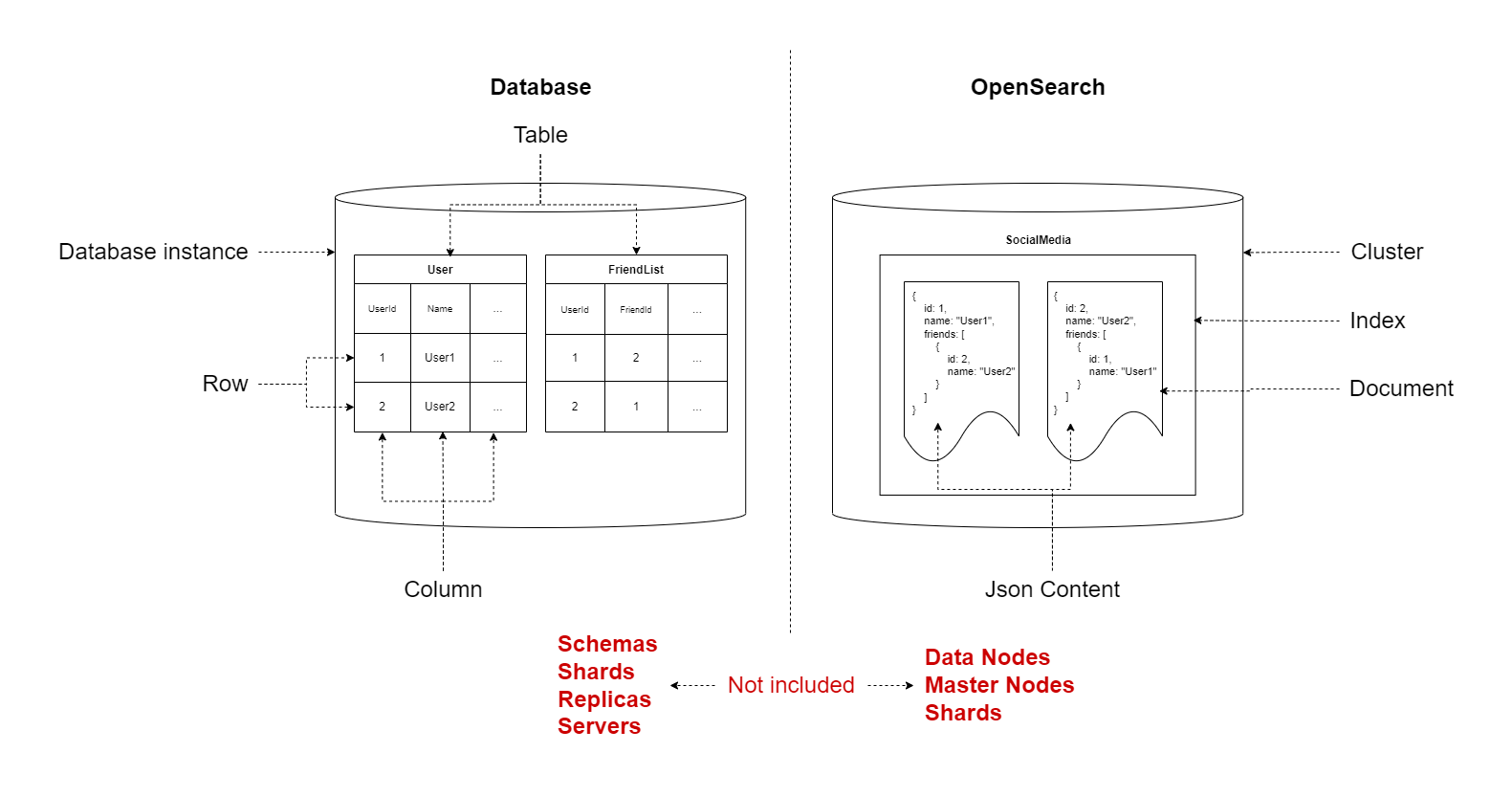
You may notice that some things are missing from these diagrams. At the moment we’re covering just enough information to get you up and running with a tutorial. However, once we establish these basic building blocks we’ll continue to increase complexity during the series.
What we see in the diagram is a data-driven perspective of a relational database and an OpenSearch cluster. The example demonstrates how we might model users and their friends in a social platform.
- A database may:
- Define two tables whose columns describe the data that is being stored
- Use primary and foreign keys to normalise the stored data and map two users together by their
UserIdto establish their friendship
- An OpenSearch cluster would:
- Define a single index
- Use each document as a self-contained data source, by storing a user’s metadata and a collection of their friends metadata alongside it
Comparing Against a Relational Database
Table v.s. Index
Much like database tables are stored in a schema in a database, OpenSearch documents are stored in an index in a cluster.
A database schema may contain many tables of different shapes and sizes, whereas a cluster may contain indices of different document shapes.
A database defines a schema for a table, whereas an index defines mappings for a document.
Normalised v.s. De-normalised data
Database tables are able to reference each other through foreign keys. This produces referential integrity, because each table is able to refer to a source of truth when making reference to an entity. It also helps to reduce duplication, as data only needs to be defined once. After this it can be referred at its place of definition moving forward.
The process of organising data to reduce duplication and redundancy is called normalisation.
OpenSearch documents on the other hand are completely self-contained. This means that the same information will be duplicated across multiple documents in OpenSearch. This leads to additional complexity in maintaining the dataset, as each document must be refreshed when a duplicated entity is updated.
Duplicating data across documents in its raw form is called de-normalisation. While there are trade-offs in the complexity of managing the data, the read performance benefits hugely from this redundancy.
Sloth Summary
There we have it. The basics of OpenSearch indexing covered! While there is still much more to learn over the coming articles, you should now have an understanding of some OpenSearch concepts and how they relate or differ to more commonly understood relational databases.
Enjoy the tutorials!