

This article will use the .Net OpenSearch.Client NuGet package. Prior to completing the tutorial please read the Keyword Field Data Type Indexing Deep Dive article as it contains useful prerequisite information.
At time of writing, Elastic.co documentation is far richer than OpenSearch, so a combination of links between the two vendors may be provided to reference the concepts discussed. These offerings are currently functionally equivalent.
Don’t forget to check out the full code samples GitHub repositories, via the Code Sloth Code Samples page.
Why Use an Adjacency Matrix?
The adjacency matrix is a tricky aggregation to wrap your head around. This is because it deeply rooted in mathematical matrices and graph theory.
If only learning OpenSearch was like the Matrix…
Unfortunately Neo isn’t here to save us. With this sadly in mind, we should understand that the adjacency matrix is useful in representing the interconnectedness of multiple filters.
Let’s take a look at the beautiful illustration below, which visually represents our upcoming code sample.
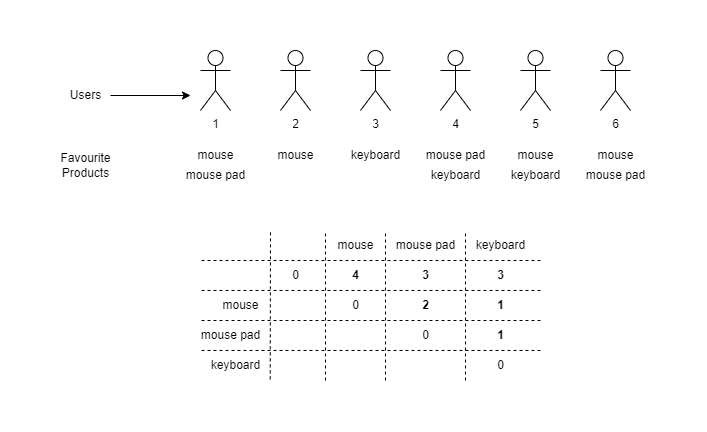
Here we have 6 users. Below each user is a list of their favourite products. If we wanted to discover the unique products that users were interested in, we could use a terms aggregation. The terms would tell us that we have 4 users who want a mouse, 3 who want a mouse pad and 3 who want a keyboard.
However, what if we wanted to learn about more complex relationships? Such as how many users want a mouse and also want a keyboard, or how many users want a keyboard and also a mouse pad.
An adjacency matrix could be used to surface these types of relationships on a shopping website in order to sell product bundles to users, or create a quick flash sale for popular product combinations.
Symmetric Matrices and Overlapping Filters
If we look at the matrix at the bottom of the image, we can see a symmetric matrix. When the matrix is sliced down the zeros on the diagonal, each half is a mirror reflection of the other. This means that we only populate mouse pad (top) and mouse (side) in the top right section with the value of 2, because the value of mouse (top) and mouse pad (side) is exactly the same. Repeating the number on the bottom half is redundant.
Each of the columns of the symmetric matrix are actually the result of a filter query. In this example, we happen to have 3 filter queries, each of which target one of our product names.
These filters could be anything that you like, however, it is important to understand that in order for the matrix to be helpful, you need to write conditions for data that overlap! For this reason, it is easy to get started writing an adjacency matrix aggregation on an array field on a document.
Adjacency Matrix Example
Let’s take a look at the code sample below:
[Fact]
public async Task KeywordMapping_CanBeUsedForAdjacencyMatrixAggregation()
{
var indexName = "keyword-index";
await _fixture.PerformActionInTestIndex<UserFavouriteProducts>(
indexName,
mapping => mapping
.Properties<UserFavouriteProducts>(propertyDescriptor => propertyDescriptor
.Keyword(word => word.Name(name => name.ProductNames))
),
async (uniqueIndexName, opensearchClient) =>
{
var userPurchasedProductDocuments = new[] {
new UserFavouriteProducts(1, new []{ "mouse", "mouse pad" }),
new UserFavouriteProducts(2, new []{ "mouse" }),
new UserFavouriteProducts(3, new []{ "keyboard" }),
new UserFavouriteProducts(4, new []{ "mouse pad", "keyboard" }),
new UserFavouriteProducts(5, new []{ "mouse", "keyboard" }),
new UserFavouriteProducts(6, new []{ "mouse", "mouse pad" }),
};
await _fixture.IndexDocuments(uniqueIndexName, userPurchasedProductDocuments);
const string userFavouriteProducts = "userFavouriteProducts";
var result = await opensearchClient.SearchAsync<UserFavouriteProducts>(selector => selector
.Index(uniqueIndexName)
.Query(query => query.MatchAll())
// We do not want any documents returned; just the aggregations
.Size(0)
.Aggregations(aggregations => aggregations
.AdjacencyMatrix(userFavouriteProducts, selector => selector
.Filters(filter => filter
.Filter("mouse", f => f.Terms(term => term.Field(f => f.ProductNames).Terms(new[] { "mouse" })))
.Filter("mouse pad", f => f.Terms(term => term.Field(f => f.ProductNames).Terms(new[] { "mouse pad" })))
.Filter("keyboard", f => f.Terms(term => term.Field(f => f.ProductNames).Terms(new[] { "keyboard" })))
)
)
));
// Extract each term and its associated number of hits
result.IsValid.Should().BeTrue();
var formattedResults = string.Join(", ", result.Aggregations
.AdjacencyMatrix(userFavouriteProducts).Buckets
.Select(bucket => $"{bucket.Key}:{bucket.DocCount}")
);
formattedResults.Should().BeEquivalentTo("keyboard:3, keyboard&mouse:1, keyboard&mouse pad:1, mouse:4, mouse pad:3, mouse&mouse pad:2");
});
}
This code sample contains a different document type to most of our other tests, such as the cardinality and terms aggregations. Let’s take a quick peek at the UserFavouriteProducts DTO:
public record UserFavouriteProducts
{
public UserFavouriteProducts(int userId, string[] productNames)
{
UserId = userId;
ProductNames = productNames;
}
public int UserId { get; init; }
public string[] ProductNames { get; init; }
}
This class is a simple DTO containing a user’s ID and an array of product names that they like. This array is the foundation of our adjacency matrix aggregation. Pretty simple!
As we can see in the test above:
- We index 6 documents to match the diagram at the beginning of the article
- We then create an adjacency matrix aggregation with 3 distinct filters
- One finds documents that have
mousein the product names array - One finds documents that have
mouse padin the product names array - One finds documents that have
keyboardin the product names array
- One finds documents that have
- The buckets of the adjacency matrix are then retrieved and stringly formatted for assertion
With this in mind let’s jump into the DebugInformation of our Adjacency matrix aggregation!
Valid OpenSearch.Client response built from a successful(200)low level call on POST: /keyword-index0af341f1-93ee-4c29-af8d-8b72782d1290/_search ? pretty = true & error_trace = true & typed_keys = true
# Audit trail of this API call :
- [1]HealthyResponse: Node: http: //localhost:9200/ Took: 00:00:00.1699662
# Request: {
"aggs": {
"userFavouriteProducts": {
"adjacency_matrix": {
"filters": {
"mouse": {
"terms": {
"productNames": ["mouse"]
}
},
"mouse pad": {
"terms": {
"productNames": ["mouse pad"]
}
},
"keyboard": {
"terms": {
"productNames": ["keyboard"]
}
}
}
}
}
},
"query": {
"match_all": {}
},
"size": 0
}
# Response: {
"took": 20,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 6,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"adjacency_matrix#userFavouriteProducts": {
"buckets": [{
"key": "keyboard",
"doc_count": 3
}, {
"key": "keyboard&mouse",
"doc_count": 1
}, {
"key": "keyboard&mouse pad",
"doc_count": 1
}, {
"key": "mouse",
"doc_count": 4
}, {
"key": "mouse pad",
"doc_count": 3
}, {
"key": "mouse&mouse pad",
"doc_count": 2
}
]
}
}
}
# TCP states:
Established: 65
TimeWait: 4
CloseWait: 3
# ThreadPool statistics:
Worker:
Busy: 1
Free: 32766
Min: 12
Max: 32767
IOCP:
Busy: 0
Free: 1000
Min: 12
Max: 1000
In the debug information we can see our adjacency matrix called adjacency_matrix#userFavouriteProducts. The keys of each bucket represent the single filter values that we wrote in our query, such as mouse, mouse pad and keyboard. The doc_count shows the number of documents that matched each filter.
We can also see some other keys in the response. keyboard&mouse, keyboard&mouse pad and mouse&mousepad represent the combination of each individual filter, with another respective filter. The doc_count for these keys represents the number of documents that matched the logical and of both filters. Note that we don’t see the reverse of these pairs, such as mouse&keyboard as they would contain the exact same value as the listed pairs and represent the “bottom half” of the symmetric matrix above.
Sloth Summary
- The adjacency matrix counts the number of documents that match each of the given filter queries
- It also counts the number of documents that match the logical
andof pairs of each filter - If targeting a single field on a document across all filters you’ll find it easier to make it an array. This is because multiple filters must each match the same document as each other to produce a result when
anded together - This type of aggregation can be useful when wanting to understand how different combinations of filters relate to each other