

This article will dive deep into the ElasticSearch Keyword field data type using samples from the CodeSloth GitHub code sample repository and the .Net OpenSearch client. We’ll explore how to define keyword mappings and take a look at the tokens that they produce when you index data into them. Finally we will answer the most confusing elastic search question by highlighting the difference between the ElasticSearch keyword vs text field data mappings at search time.
At time of writing, Elastic.co documentation is far richer than that published by OpenSearch. Therefore a combination of links between the two vendors may be provided to reference the concepts discussed. These offerings are currently functionally equivalent so the word ElasticSearch and OpenSearch may be used interchangeably.
What is an ElasticSearch Keyword?
The keyword field data type is a simple data type that we can use to index raw .Net strings. In order to use this data type, simply define a class or record with a string property, such as the ProductDocument in the KeywordDemo .Net test Project.
public record ProductDocument
{
...
/// <summary>
/// This string property will be mapped as a keyword
/// Conceptually this property may represent the name of a product
/// </summary>
public string Name { get; init; }
}
How is a Keyword Mapped in .Net?
The mapping of a keyword is very simple. As is the case with all mappings, we invoke the Map method on a CreateIndexDescriptor. This can be seen in IndexFixture.PerformActionInTestIndex.
var createIndexDescriptor = new CreateIndexDescriptor(uniqueIndexName)
.Map(mappingDescriptor);
The Map function takes a Function which provides a TypeMappingDescriptor parameter, which we can use to define our mappings. Mappings are defined by calling the Properties method on the TypeMappingDescriptor and specifying the properties of our .Net class that we would like to store data for, along with the way that we would like OpenSearch to index that data.
/// <summary> /// This function is used to define a keyword mapping for the Name of a product /// Opensearch documentation: https://opensearch.org/docs/2.0/opensearch/supported-field-types/keyword/ /// ElasticSearch documentation is far richer in very similar detail: https://www.elastic.co/guide/en/elasticsearch/reference/current/keyword.html /// </summary> Func<TypeMappingDescriptor<ProductDocument>, ITypeMapping> mappingDescriptor = mapping => mapping .Properties<ProductDocument>(propertyDescriptor => propertyDescriptor .Keyword(word => word.Name(name => name.Name)) );
As we can see in the example above, our KeywordTests class calls the Keyword method to map an ElasticSearch keyword field data type. The Name(...) method on the KeywordPropertyDescriptor then let’s us use an expression tree to map the property of our ProductDocument that we want to be indexed as a keyword. Coincidentally this property is also called Name.
While the OpenSearch and ElasticSearch .Net clients support string inputs, it’s best to leverage expression trees when defining mappings or writing queries. This helps to avoid a growing number of string constants in your code and keeps the field names in alignment with your DTOs should they change over time. You’ll also be able to find all references in Visual Studio to see how the data of the property is populated, alongside how it is mapped into OpenSearch.
Once we have created our CreateMappingDescriptor we simply need to use it when creating our new index!
var indexCreationResult = await _openSearchClient.Indices.CreateAsync(uniqueIndexName, descriptor => createIndexDescriptor);
In the sample above we can see the .Net opensearch client calling CreateAsync on the Indices property, specifying an index name and passing through the descriptor. Simple!
Inspecting the ElasticSearch Keyword Mapping Using CodeSloth Samples
Firstly start by running a local OpenSearch cluster in Docker.
Using Visual Studio, launch the codesloth-opensearch-samples solution file. Set a breakpoint in the first line of the async lambda given to the PerformActionInTestIndex method, as seen below.
Using the Test Explorer, debug the test. Once the breakpoint has been hit, open your Chrome browser and launch ElasticSearch Head and locate the test index. You can learn more about ElasticSearch Head here.
Select Info -> Index Metadata. Locate the Mappings section. This typically sits under Settings in the JSON content.
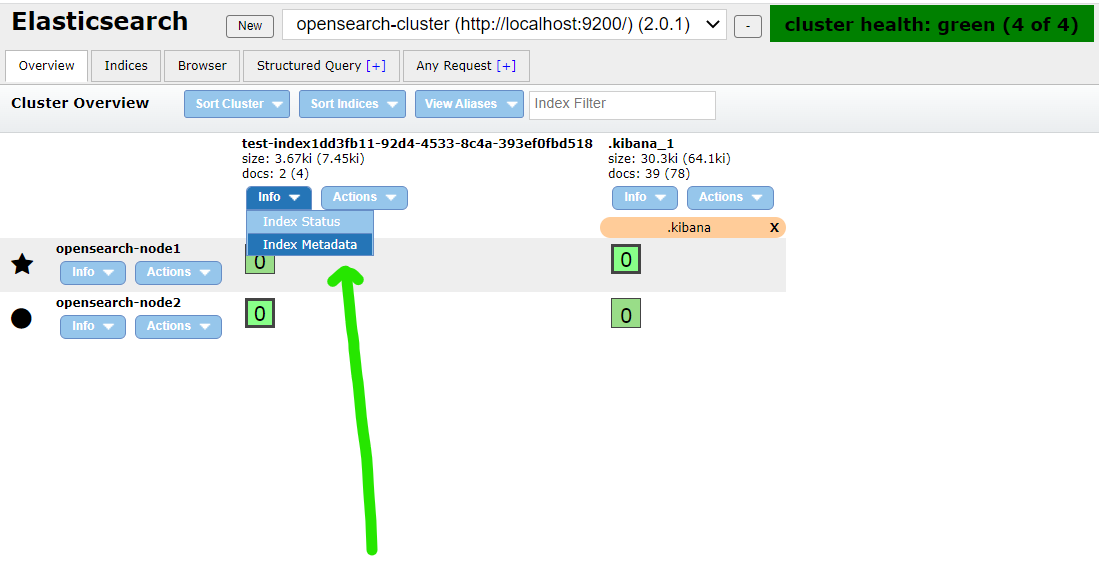
The keyword mapping for our document looks like this:
"mappings": {
"_doc": {
"properties": {
"name": {
"type": "keyword"
},
...
}
}
}
Yep. That’s it. Pretty basic huh?
ElasticSearch Keyword Analysis (or Lack Thereof)
Despite keywords being simple, they are likely going to form a common part of your toolset if you require exact string matching in your search experience. This is because the keyword analyser does nothing and produces a single token. Single tokens imply exact string matching on a search term.
Analysers are a core part of enabling a rich full text search experience. They can contain three parts: character filters, tokenisers and token filters, all of which do nothing for keyword analysis. We’ll cover this in more detail during a deep dive into the text field data type.
Let’s objectify our tokenisation claims with some data.
Observing the Keyword Token
The test case below will index a single document that contains a parameterised termText string. The CodeSloth code sample actually evaluates different types of string inputs, but we’ve focused on the most complex one for the example below.
The complexity of the string can be observed through its use of:
- Capital and lowercase letters
- Punctuation such as exclamation mark, comma, full stop and semicolon
- Known English Stop Words (words removed from tokenisation by a stop token filter)
Each of these components could be subject to omission or modification during text based tokenisation.
[Theory]
...
[InlineData("This is a sentence! It contains some, really bad. Grammar;", "All grammar is indexed exactly as given")]
public async Task KeywordMapping_IndexesASingleTokenForGivenString(string termText, string explanation)
{
var indexName = "keyword-index";
await _fixture.PerformActionInTestIndex(
indexName,
mappingDescriptor,
async (uniqueIndexName, opensearchClient) =>
{
var productDocument = new ProductDocument(1, termText);
await _fixture.IndexDocuments(uniqueIndexName, new[] { productDocument });
var result = await opensearchClient.TermVectorsAsync<ProductDocument>(selector => selector
.Index(uniqueIndexName)
.Document(productDocument)
);
result.IsValid.Should().BeTrue();
var tokensAndFrequency = string.Join(", ", result.TermVectors.Values.SelectMany(value => value.Terms.Select(term => $"{term.Key}:{term.Value.TermFrequency}")));
var expectedTokenCsv = $"{termText}:1";
tokensAndFrequency.Should().BeEquivalentTo(expectedTokenCsv, explanation);
}
);
}
The test method above:
- Leverages the
keywordmapping descriptor above in creating an ephemeral testing index - The async callback then creates a
ProductDocumentand indexes it into the OpenSearch cluster - It then runs a
TermVectorAsyncquery to find the tokens that were produced - It asserts that we have a single token that matches the string
We can observe the indexed document using ElasticSearch Head’s Structured Query tab, :
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [{
"_index": "keyword-index6958c373-cdd1-4435-bf48-d247cb9882bf",
"_id": "1",
"_score": 1,
"_source": {
"id": 1,
"name": "This is a sentence! It contains some, really bad. Grammar;"
}
}
]
}
}
As we can see, the name field of the _source document contains exactly the termText that the test was given. It is important to understand though, that the _source document only contains the original indexed data and is not used to perform the search itself!
To confirm that our field has produced a single token we can query the Term Vectors API using TermVectorsAsync on the OpenSearch client. This will return us each generated token and the number of times that it appeared in a given string for a specific document.
Looking at the DebugInformation of the term vector query of our test method above, we can see that is produces:
Valid OpenSearch.Client response built from a successful (200) low level call on POST: /keyword-indexa5b2e365-af3c-4b5b-a01a-1809dd520563/_termvectors?pretty=true&error_trace=true
# Audit trail of this API call:
- [1] HealthyResponse: Node: http://localhost:9200/ Took: 00:00:01.0232200
# Request:
{"doc":{"id":1,"name":"This is a sentence! It contains some, really bad. Grammar;"}}
# Response:
{
"_index" : "keyword-indexa5b2e365-af3c-4b5b-a01a-1809dd520563",
"_version" : 0,
"found" : true,
"took" : 586,
"term_vectors" : {
"name" : {
"field_statistics" : {
"sum_doc_freq" : 1,
"doc_count" : 1,
"sum_ttf" : 1
},
"terms" : {
"This is a sentence! It contains some, really bad. Grammar;" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 0,
"start_offset" : 0,
"end_offset" : 58
}
]
}
}
}
}
}
# TCP states:
Established: 103
TimeWait: 23
CloseWait: 9
# ThreadPool statistics:
Worker:
Busy: 1
Free: 32766
Min: 12
Max: 32767
IOCP:
Busy: 0
Free: 1000
Min: 12
Max: 1000
This response confirms that we have a single term in the response (found under the terms property), which reflects our original (unmodified) string. The term_freq indicates that this token has only been found once, which makes sense because the whole string has created a single token.
Our test above affirms this for us, by concatenating the parameterised termText against the value 1 and performing an equivalence comparison against the results of the term vector query, which are formatted in the same way.
ElasticSearch Keyword vs Text
It can be confusing to understand the difference between keyword and text mappings when starting out with OpenSearch. This confusion then worsens when you start to consider term v.s. match query types for executing a search.
From an indexing perspective, remember:
- Keywords: produce a single token. The keyword analyser does nothing to a given string
- Text: may produce more than one token. The default analyzer is the standard analyser
The details of searching keyword mappings can be found in this article on querying the keyword field data type. In summary:
| Keyword mapping | Text Mapping | |
| Term query | Exact match search | Will only match documents that produce a single token. This means that strings which contain spaces will not match, as the standard analyzer creates shingles from the input string |
| Match query | Exact match search. Query string is not tokenised. | Scored search on tokens. Query string is tokenised. |
Sloth Summary
ElasticSearch Keywords are a powerful tool for exact string search. They are often confused with text mappings, but are the much simpler version to being working with.
We learned how to create an index that has an ElasticSearch keyword field using a .Net DTO, index data into it and observe the tokens produced. For more information on querying keyword data check out this article.
Remember to check out the GitHub links in the code samples page for the complete references to snippets included in this article!